Semistructured Merge: Rethinking Merge in Revision Control Systems
Sven Apel, Jörg Liebig, Benjamin Brandl, Christian Lengauer, Christian Kästner
Overview
This website contains the results of an empirical study on semistructured and unstructured merge with regard to their abilities to resolve merge conflicts. The two merge approaches, the tool, and the empirical study are described in detail in a
scientific paper.
The study was conducted using the tool
FeatureHouse, which implements (amongst others) the two merge approaches. To compare semistructured and unstructured merge, FeatureHouse creates for each two revisions of a file (and its common base revision) two new output files, one containing the result of unstructured merge and one containing the result of semistructured merge.
Distribution
The distribution contains a binary (jar file) with the merge tool, sample projects that we used to evaluate our approach (examples), scripts to analyze the output of the merge tool (evaluation), and a scientific paper describing the approach.
How To
FeatureHouse expects the input revisions listed in a file, containing the directories of the revisions to merge in top-down order: first revision, base revision, second revision (three-way merge). Detailed information on how to use the tool and how to analyze the results can be found in the distribution (README.TXT).
In a nutshell, the merge algorithm is applied by invoking FeatureHouse as follows:
java -cp featurehouse.jar merger.FSTGenMerger --expression <revisions file>
For example, merging the revisions 4676 and 4998 of the sample project jEdit, one has to invoke:
java -cp featurehouse.jar merger.FSTGenMerger --expression ../examples/jEdit/rev4676-4998/rev4676-4998.revisions
Note, as a prerequisite,
Linux's merge tool has to be installed on the system. Beware a single run can take considerable time (hours for large projects).
After merging, the results are stored in a corresponding folder, for the above example, in folder
../examples/jEdit/rev4676-4998/rev4676-4998.
Analysis
We used a number of scripts to analyze the output of the merge process. First, we sum up all merge conflicts that occur in a project (using
./writeAllResults-JAVA.sh,
./writeResults-PY.sh, and
./writeResults-CS.sh). The scripts create two
.csv files (one for unstructured merge and one for semistructured merge):
./writeAllResults-JAVA.sh ../examples/jEdit/
Then, all results and diagrams are computed with
statistics tool R. The R scripts (
Diagrams.R and
Percentages.R) are applied to the
.csv files and create corresponding bar diagrams and tables:
R -f Diagrams.R
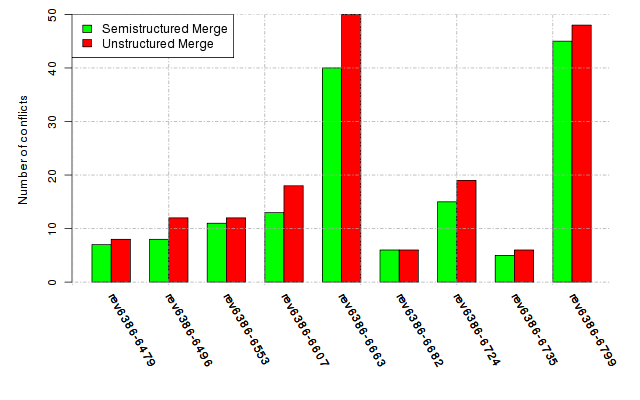
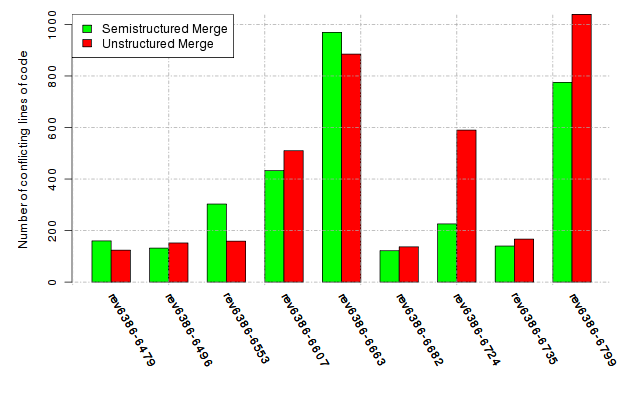
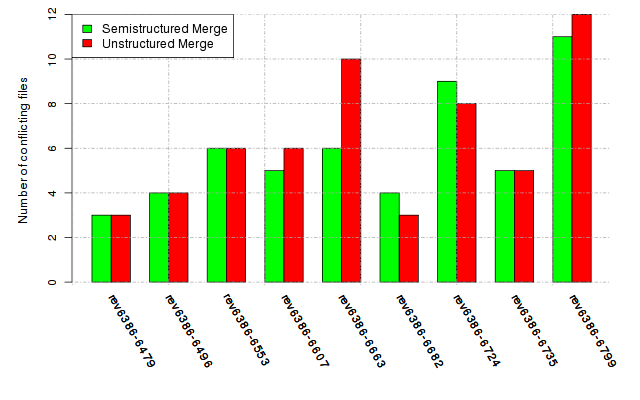
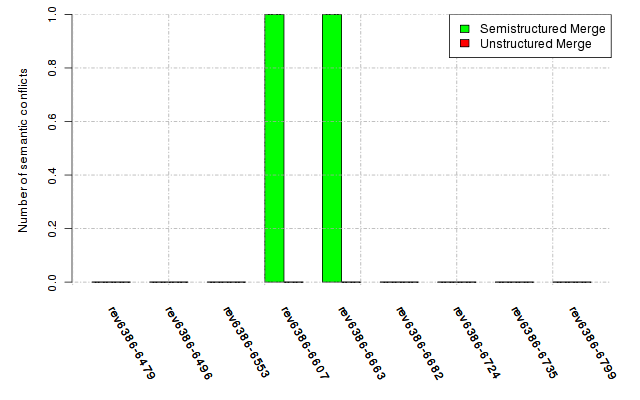
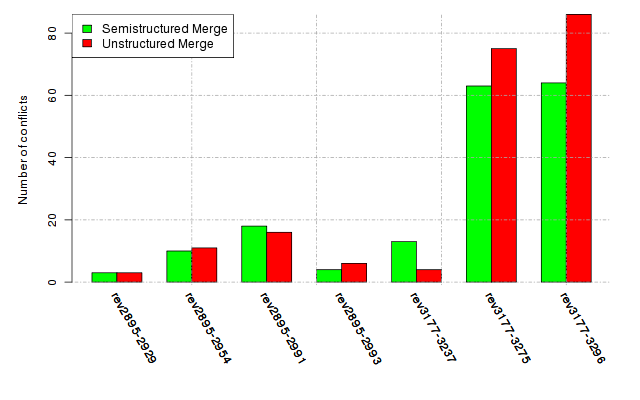
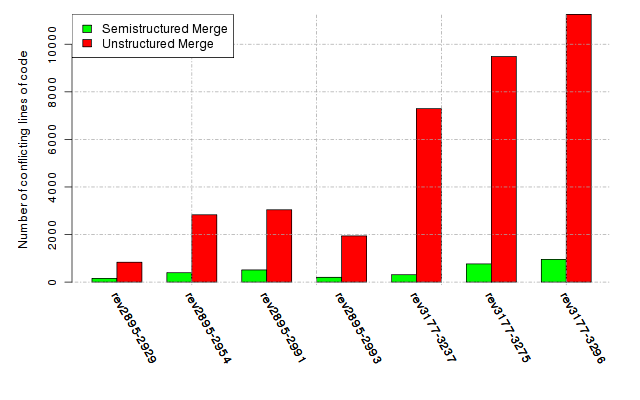
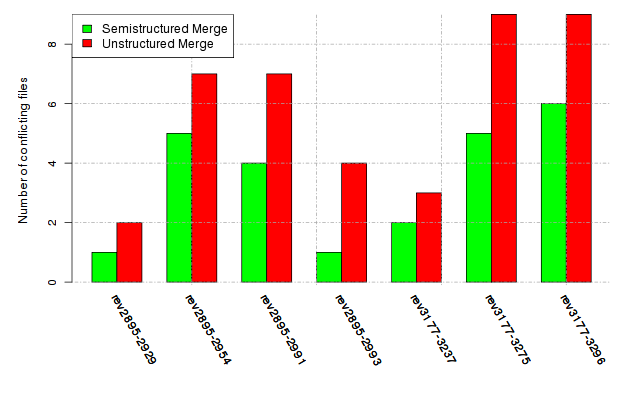
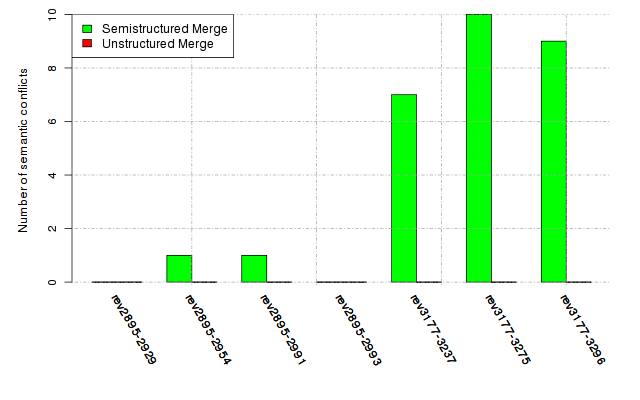
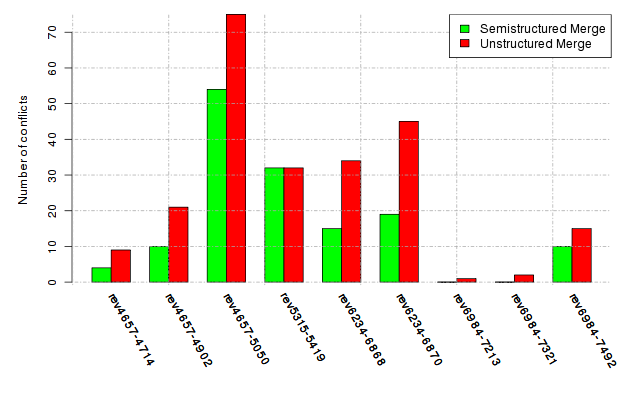
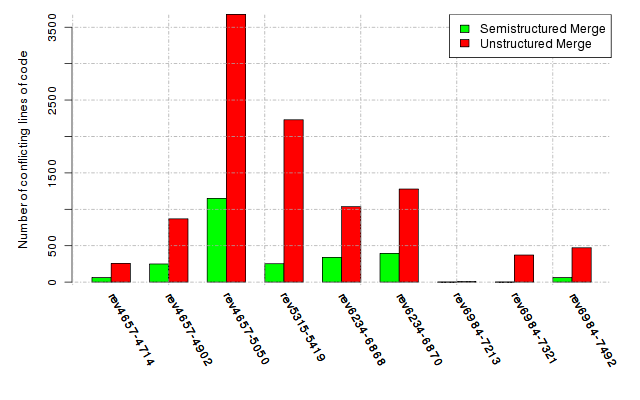
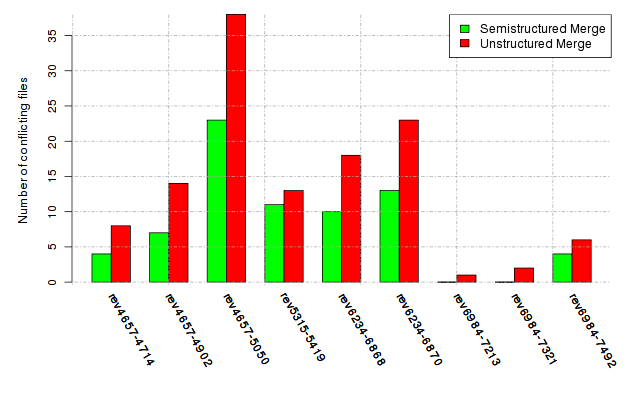
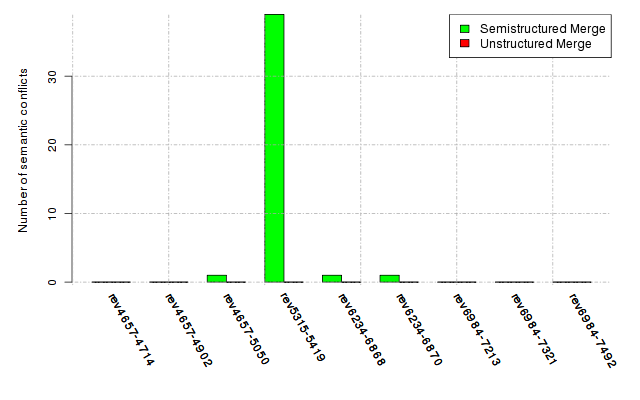
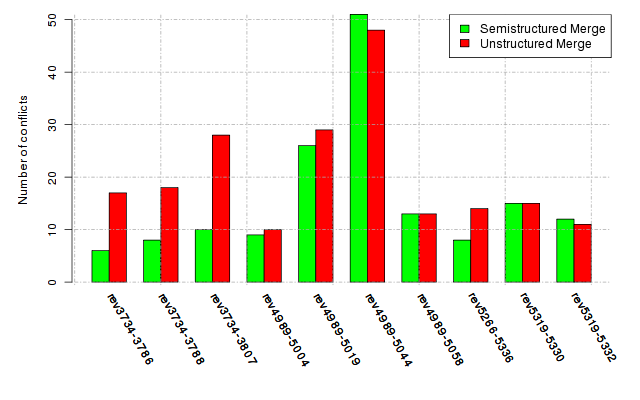
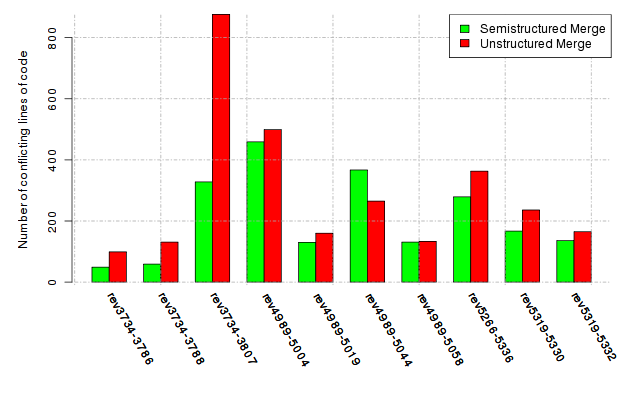
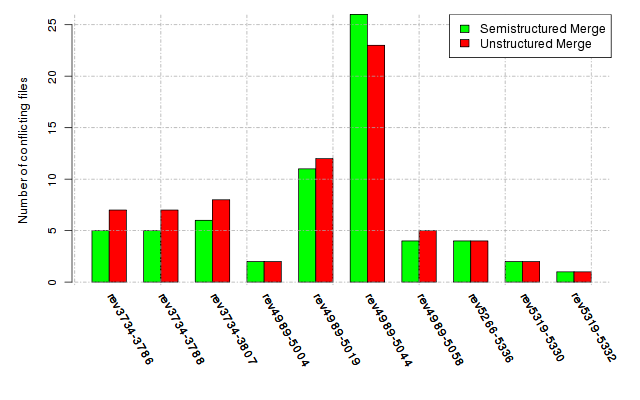
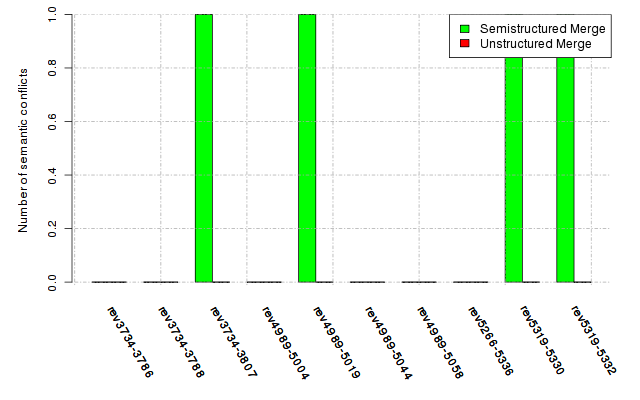
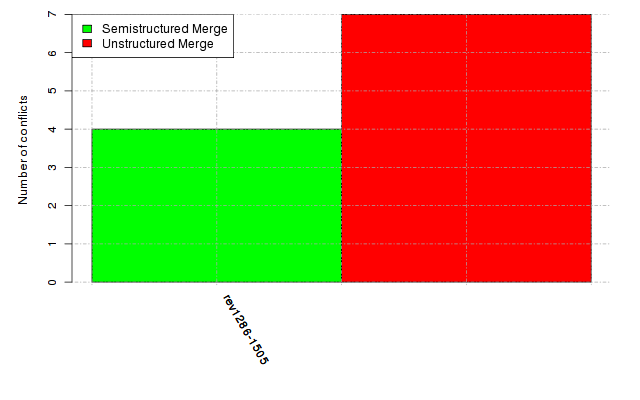
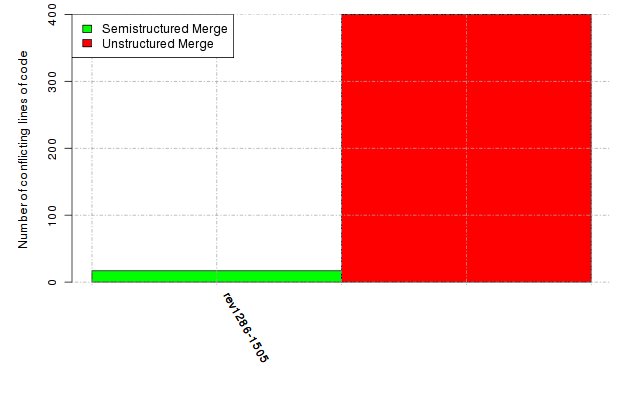
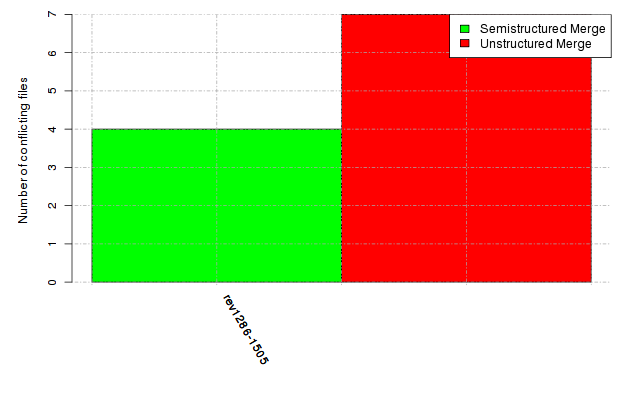
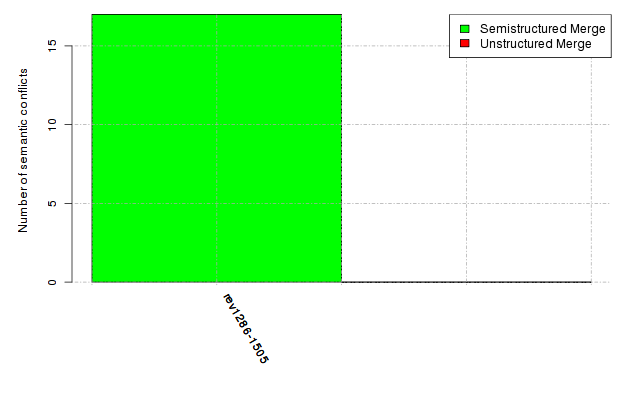
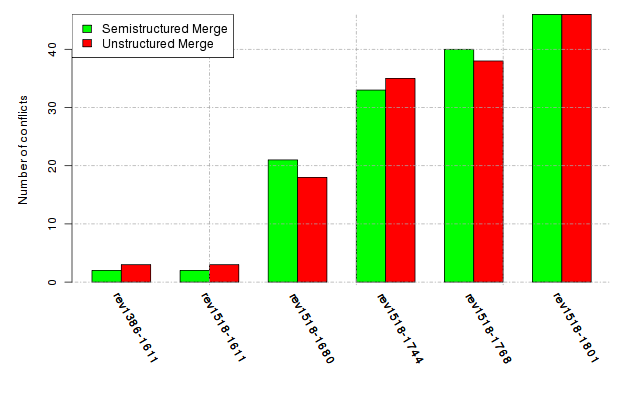
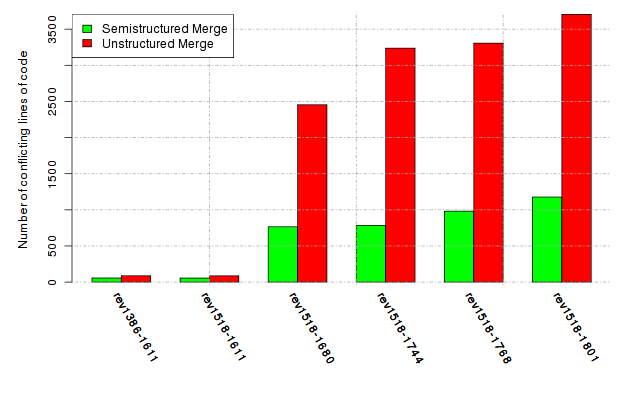
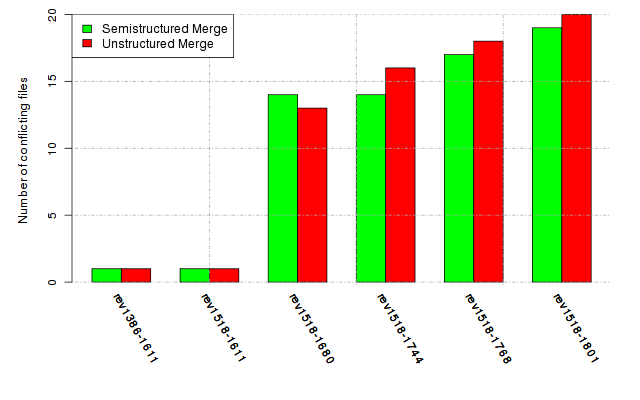
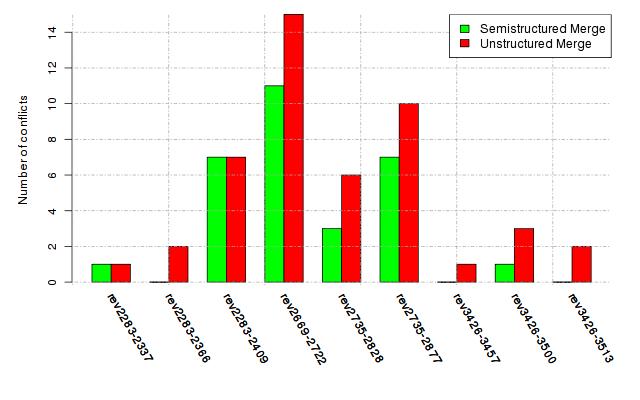
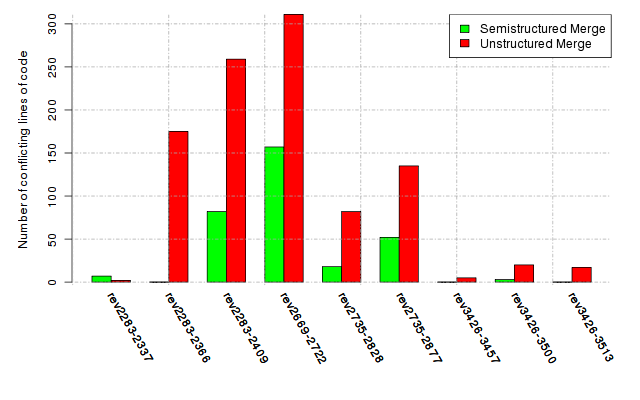
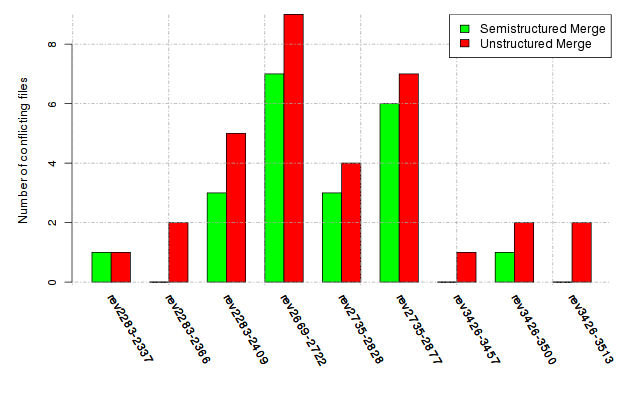
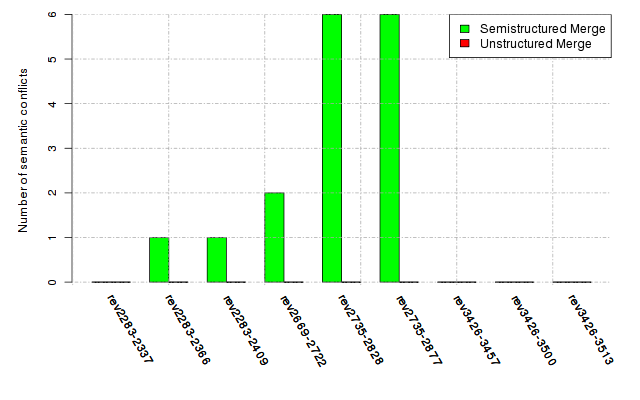
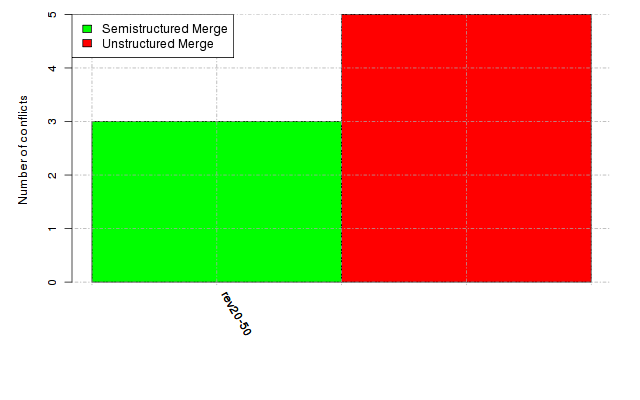
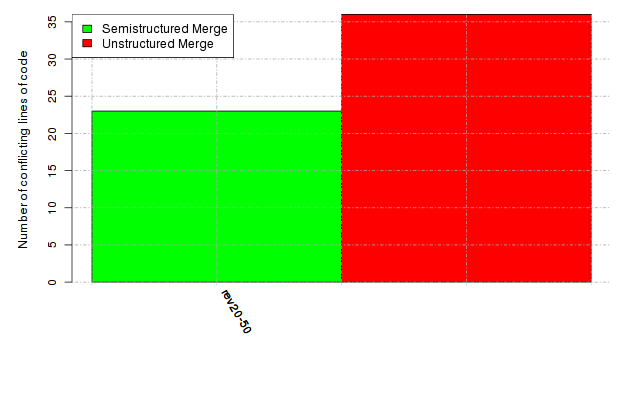
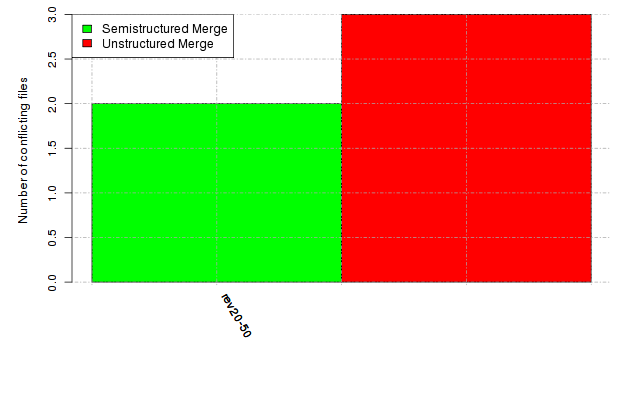
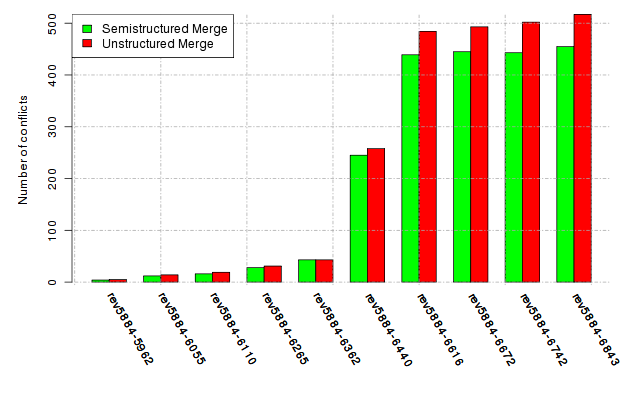
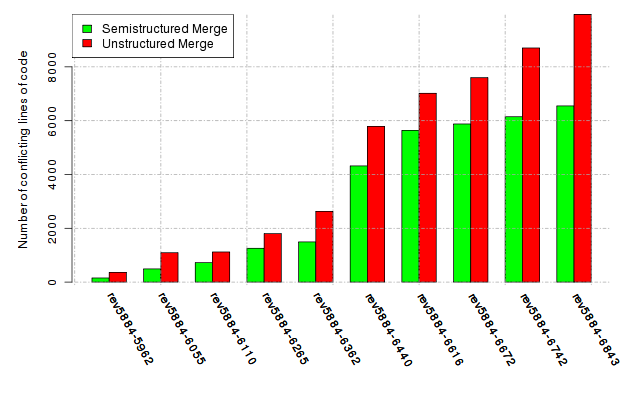
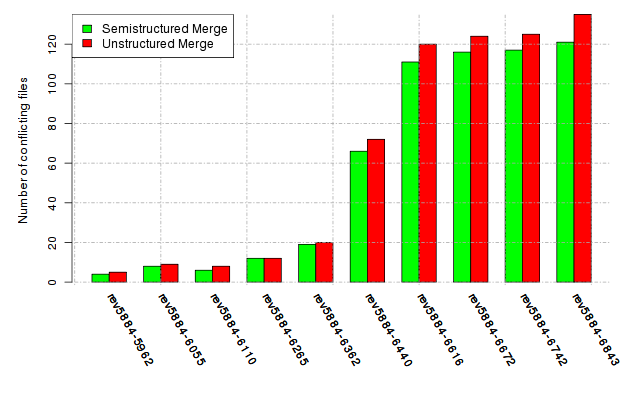
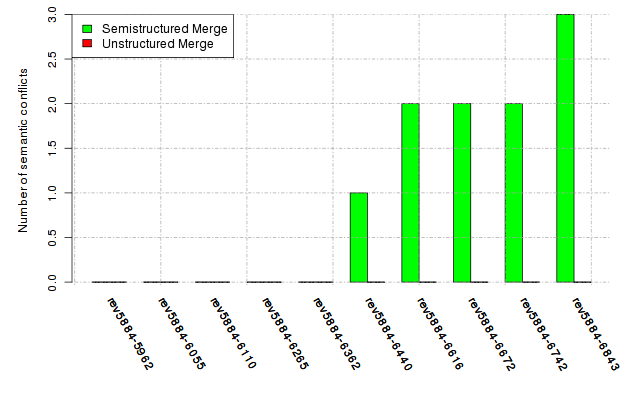
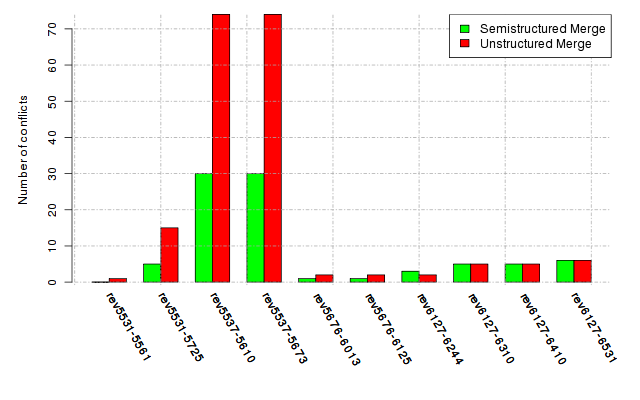
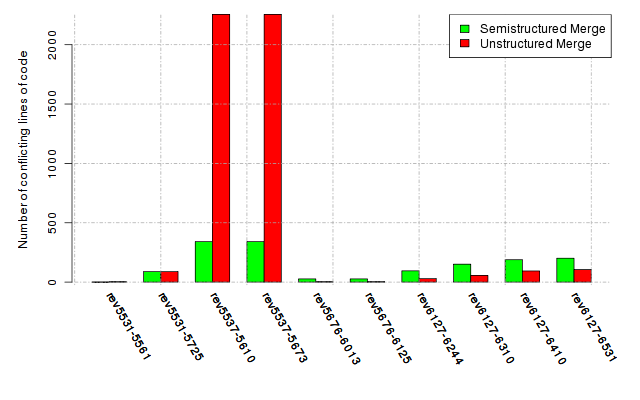
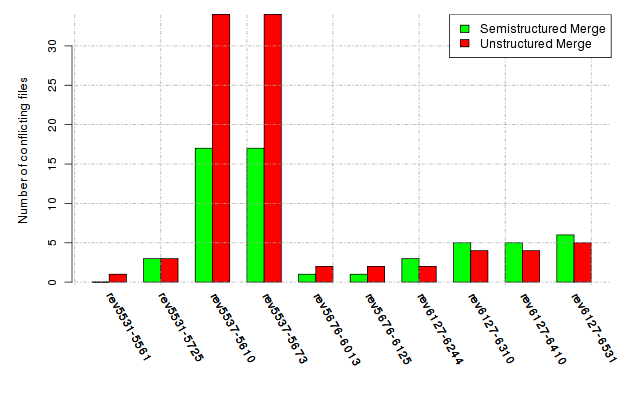
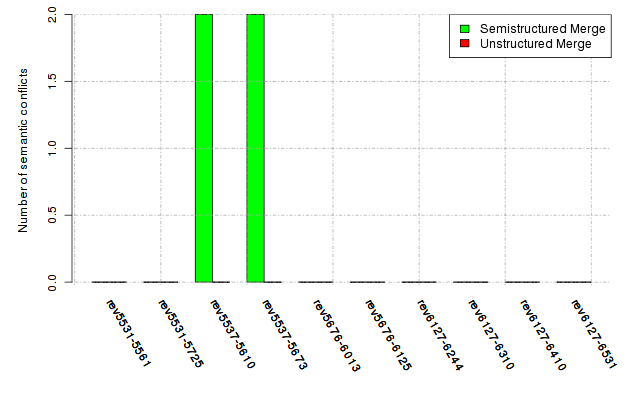
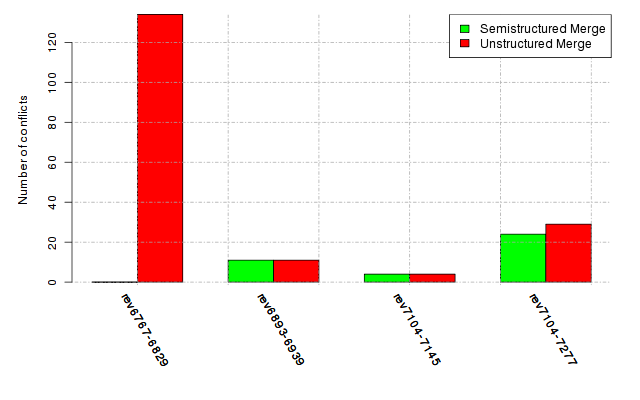
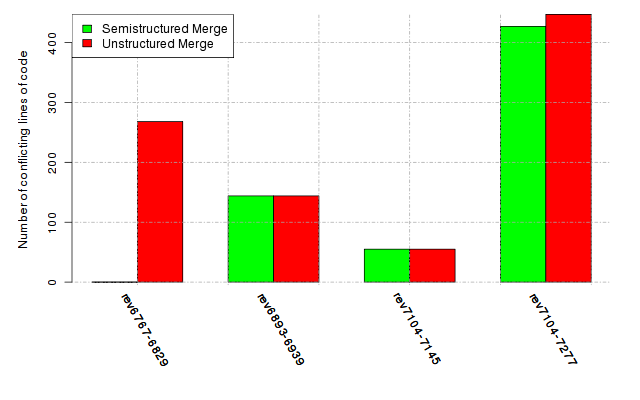
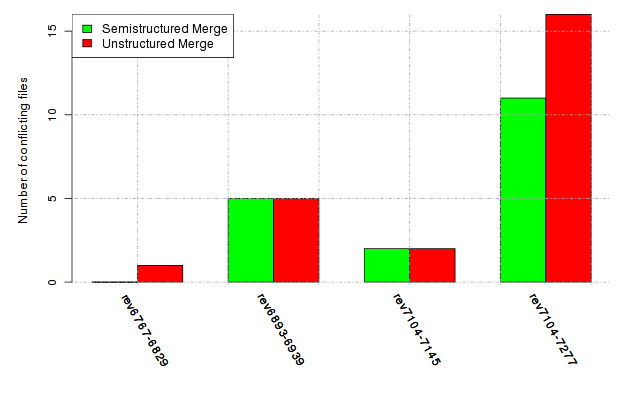
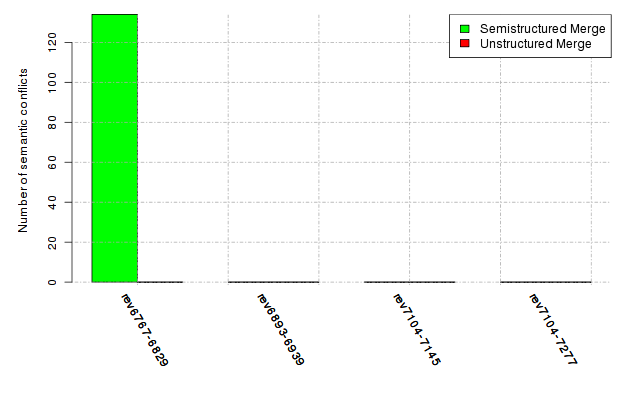
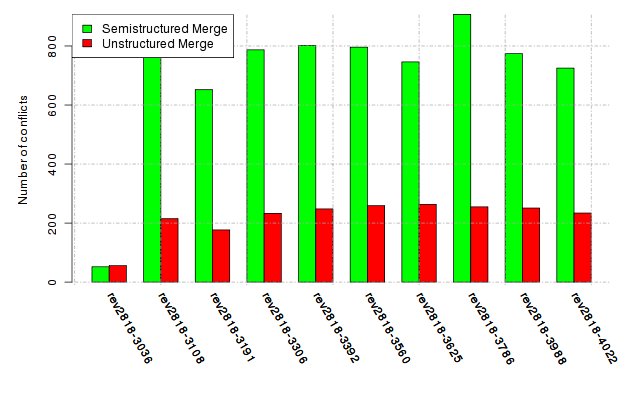
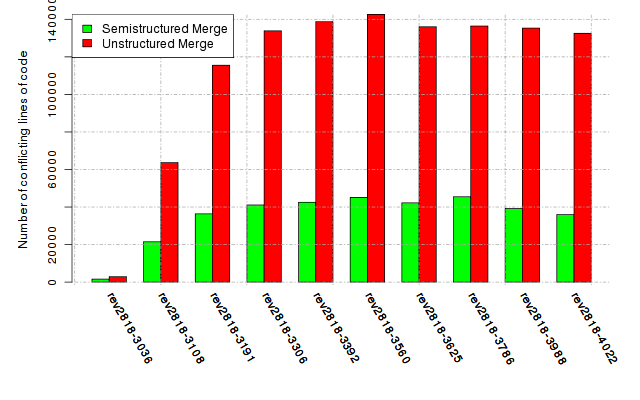
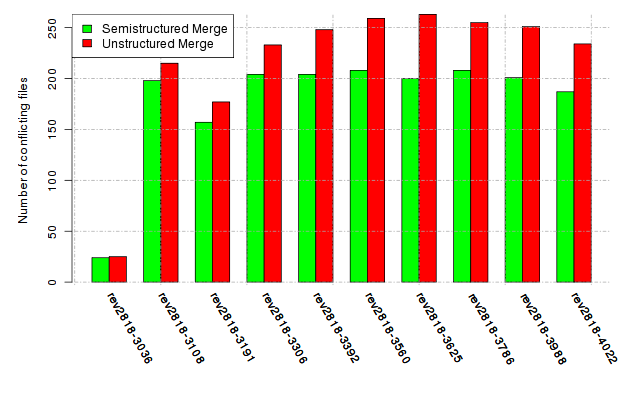
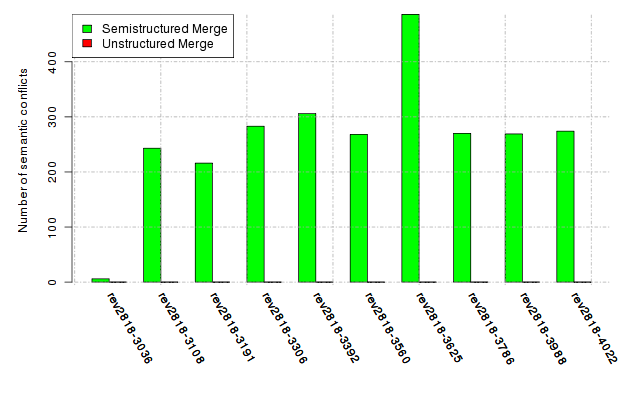
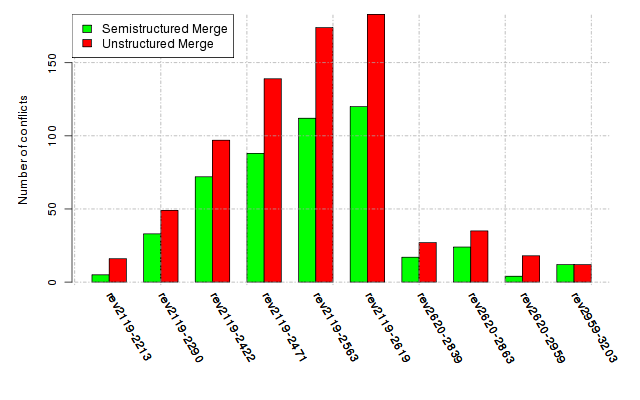
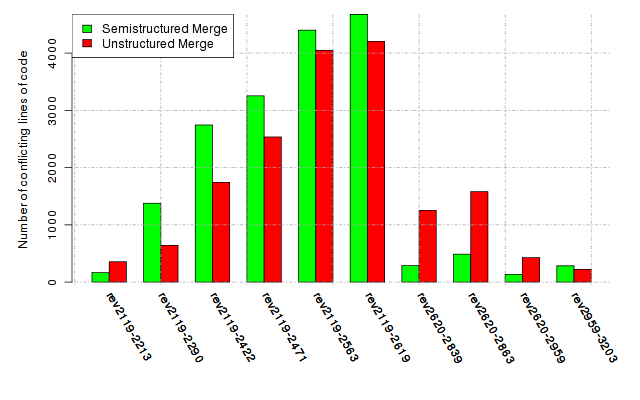
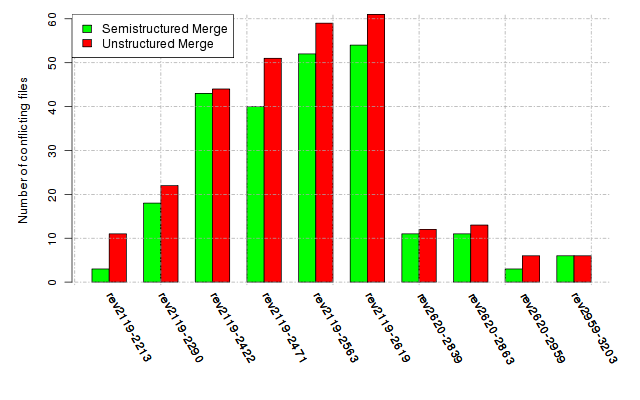
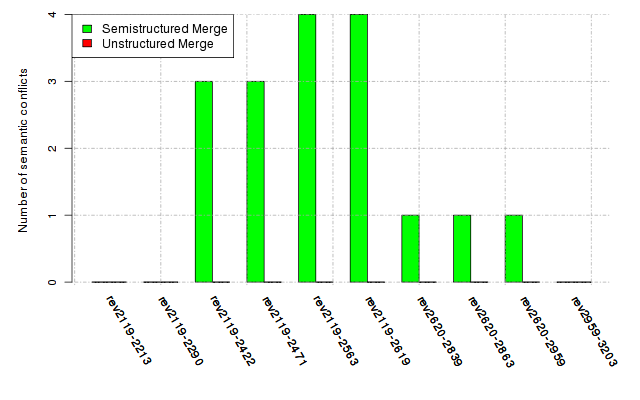
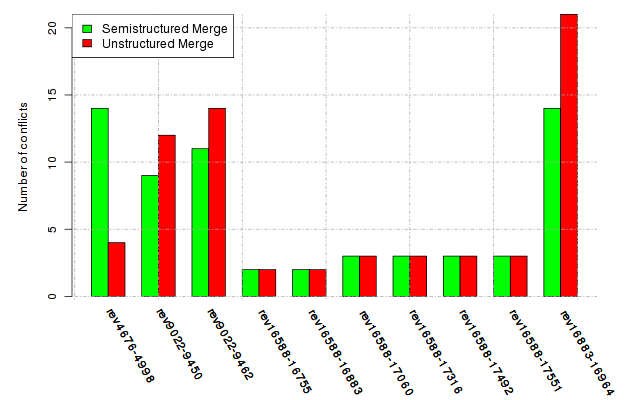
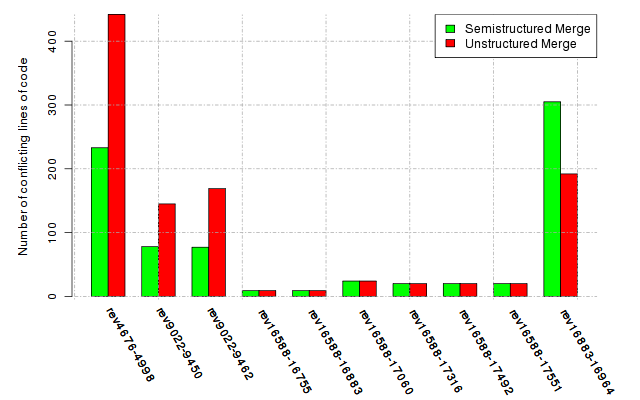
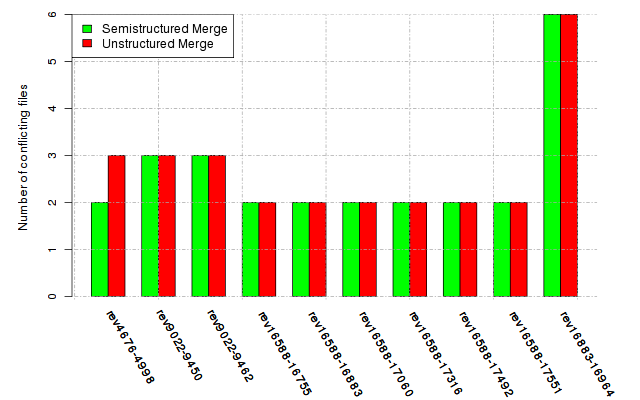
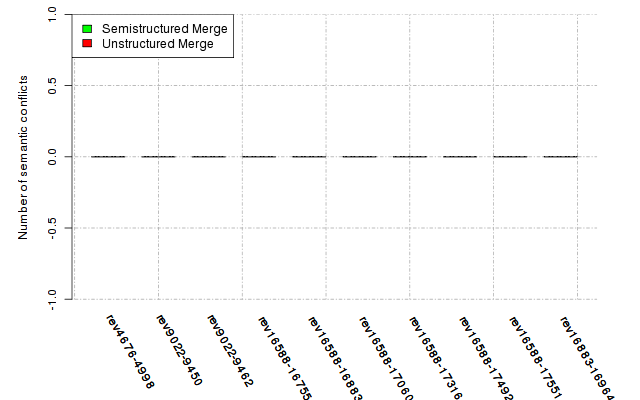
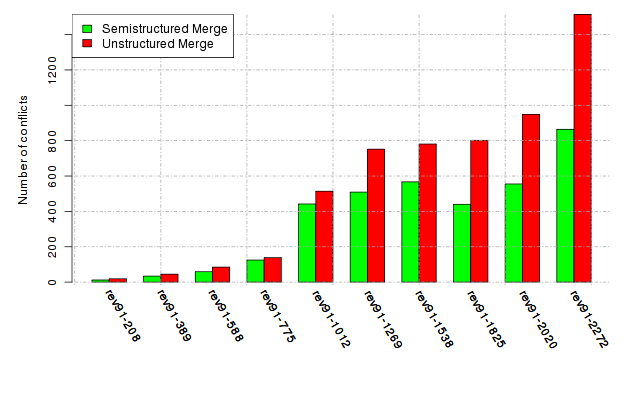
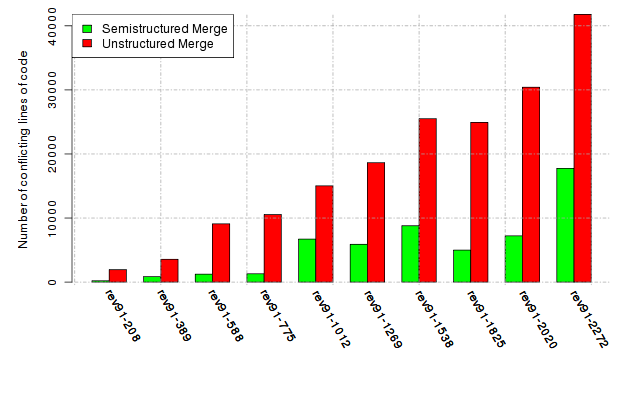
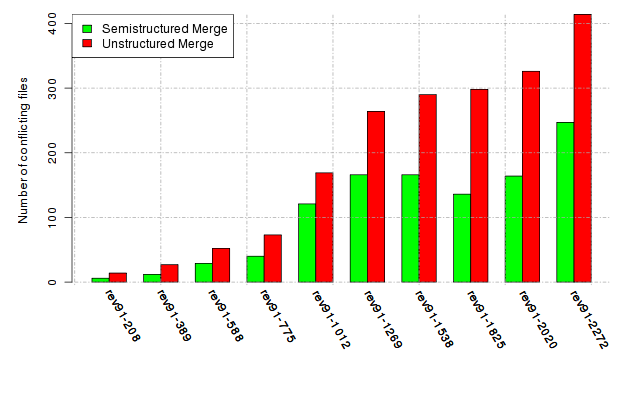
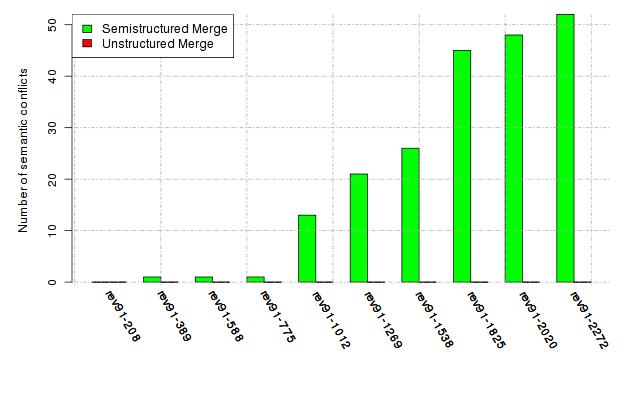
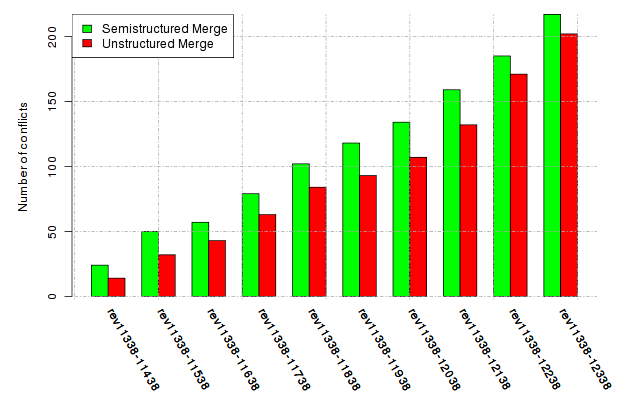
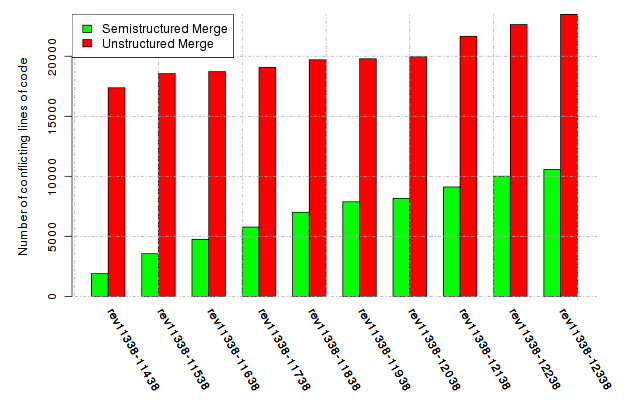
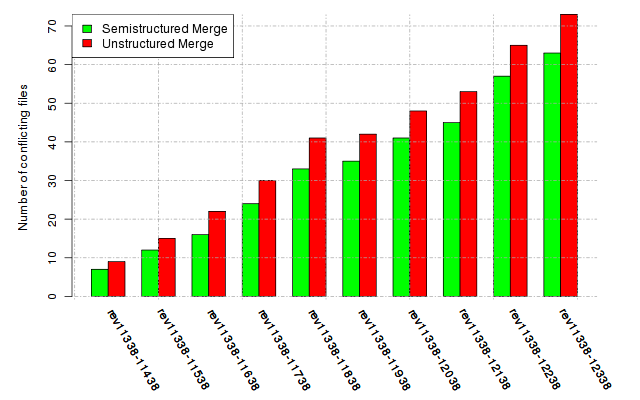
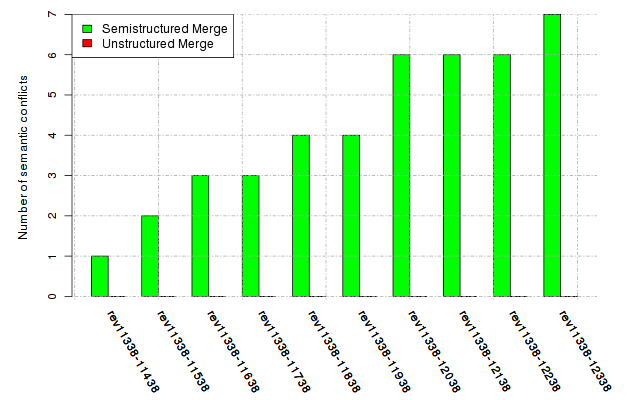
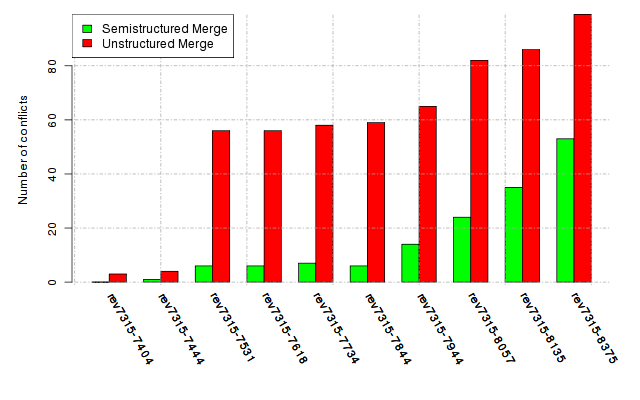
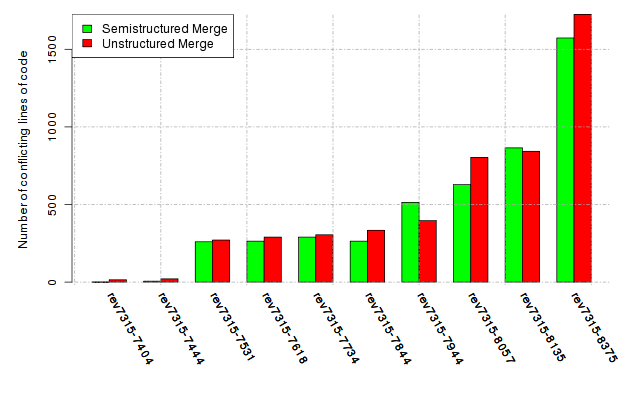
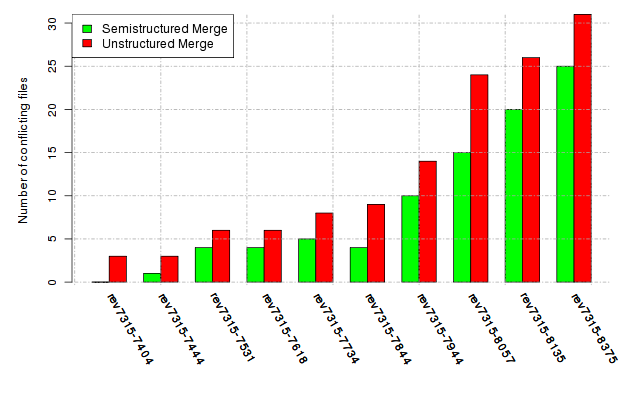
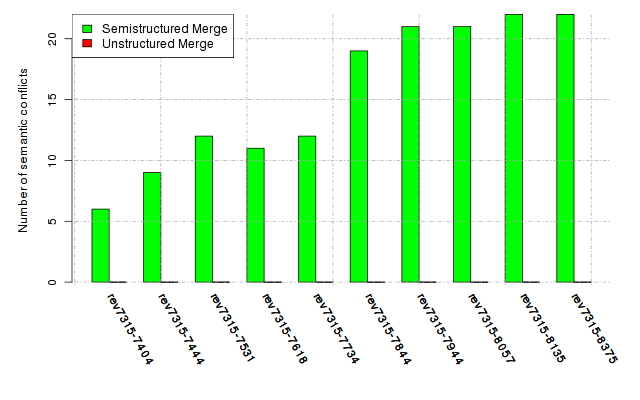
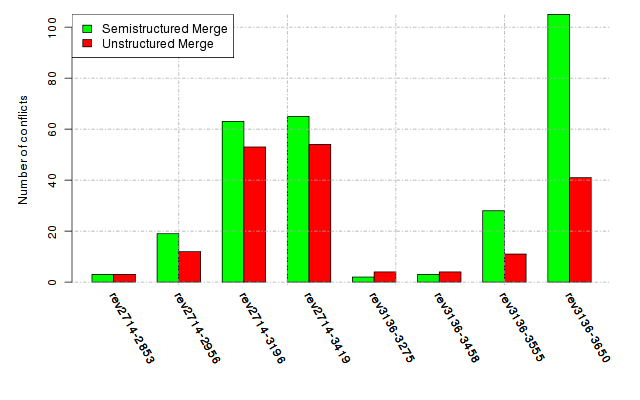
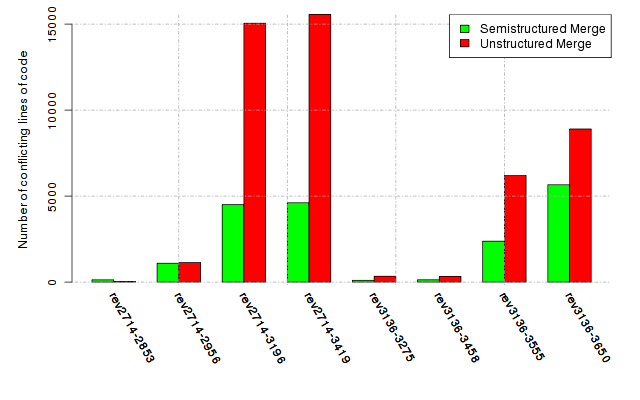
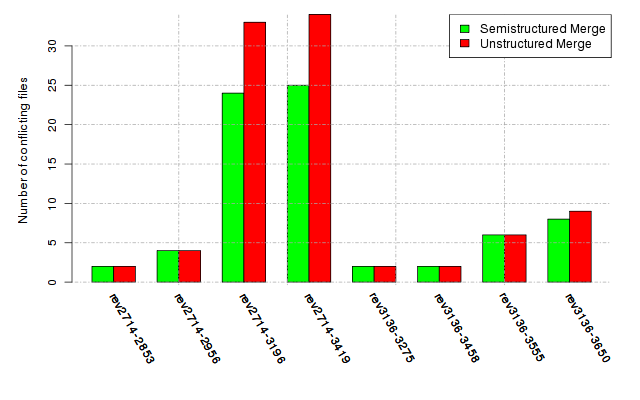
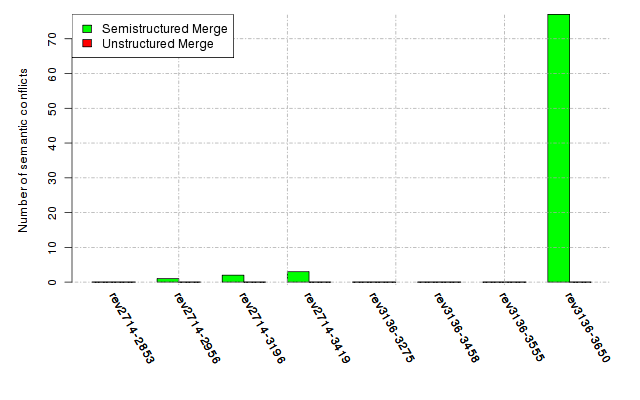
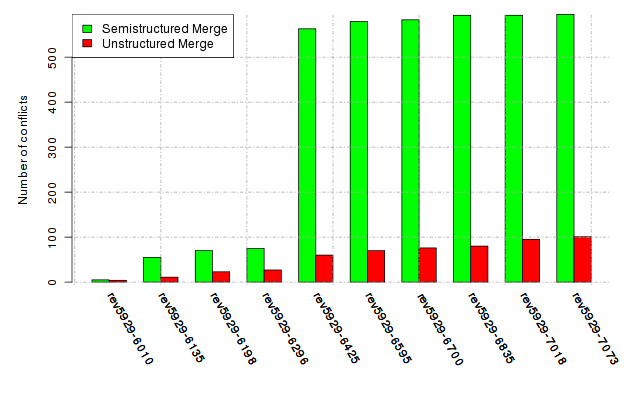
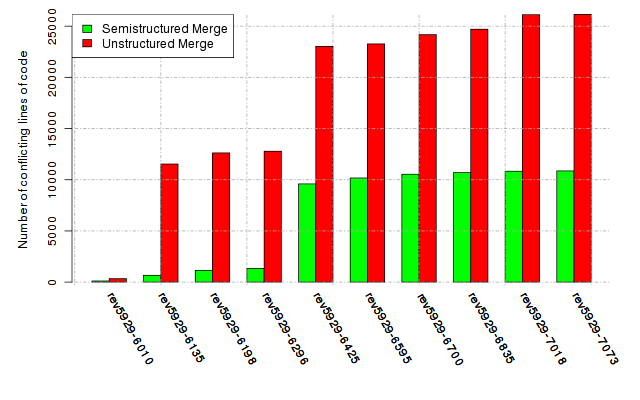
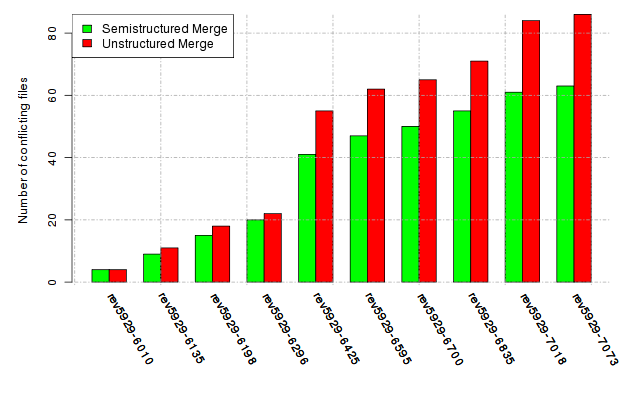
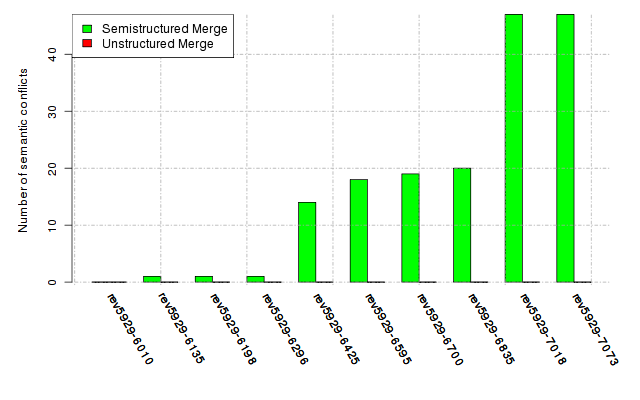
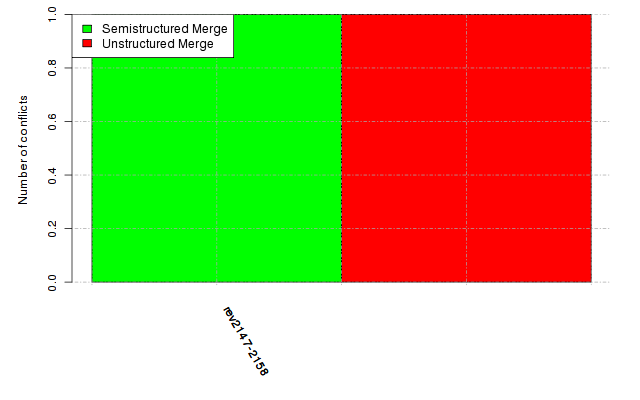
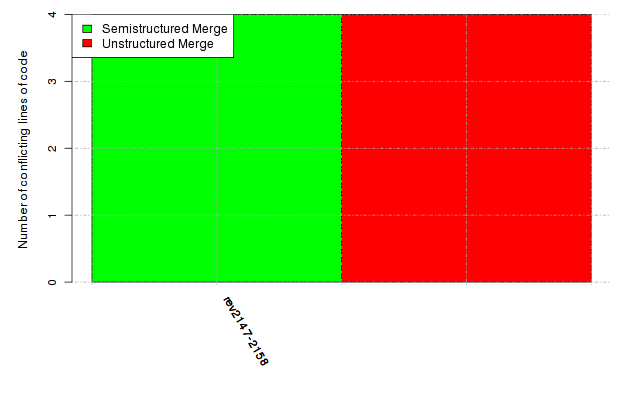
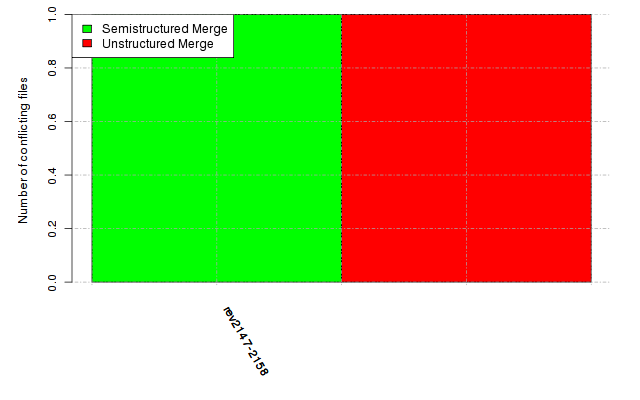
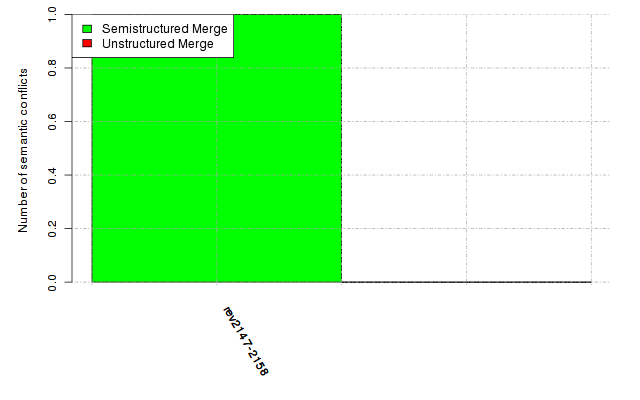
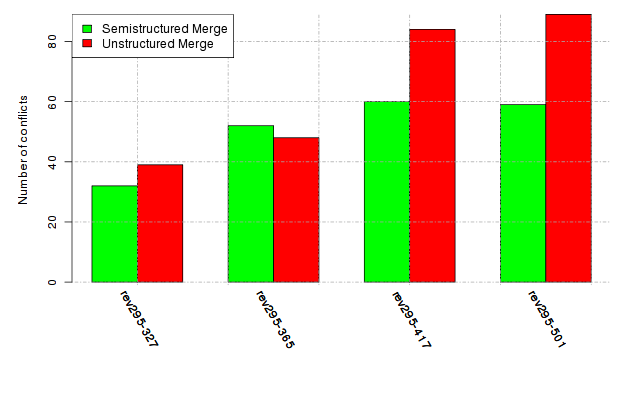
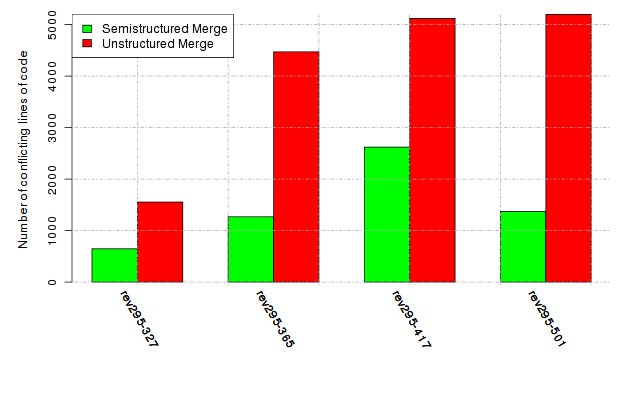
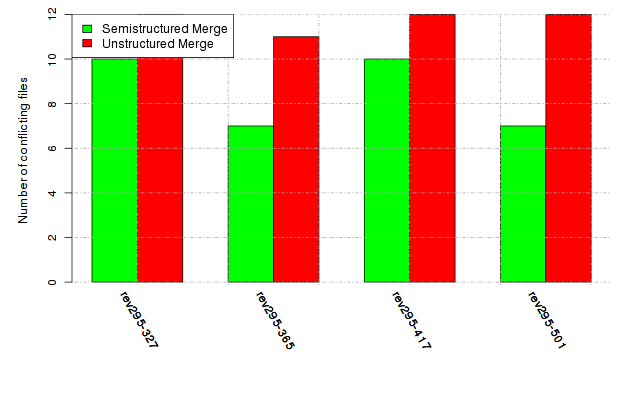
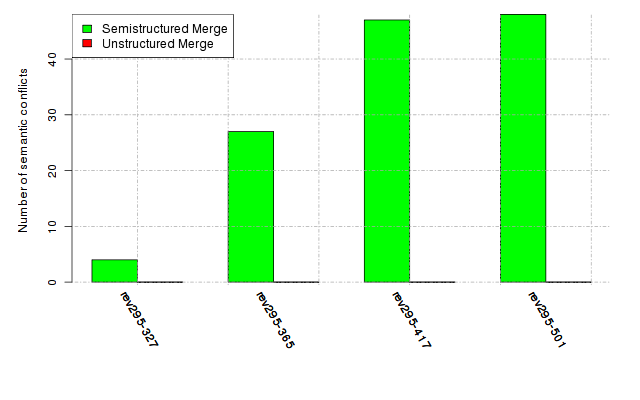
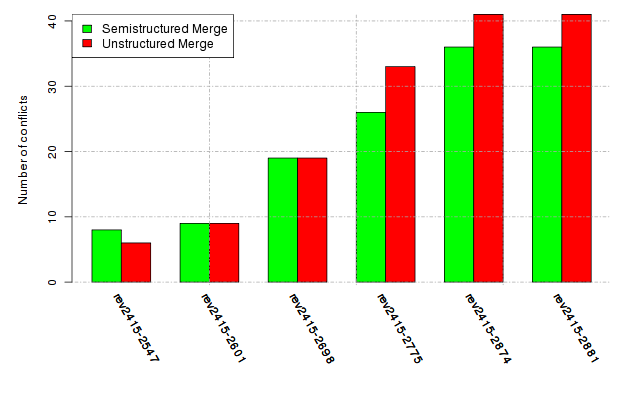
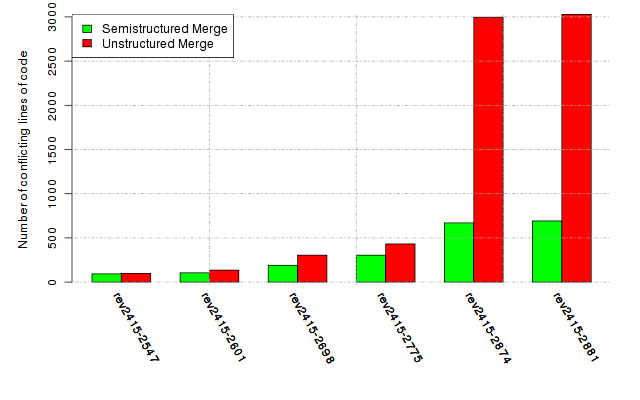
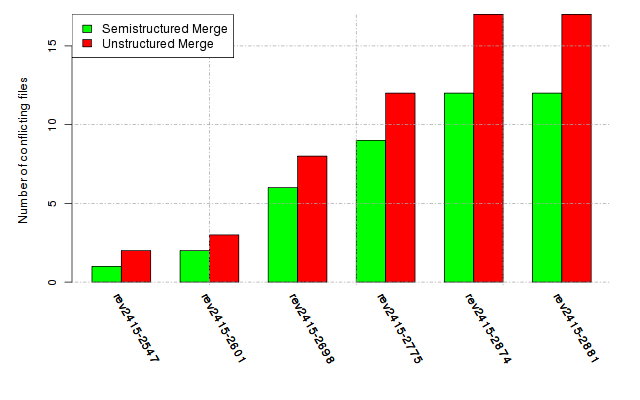
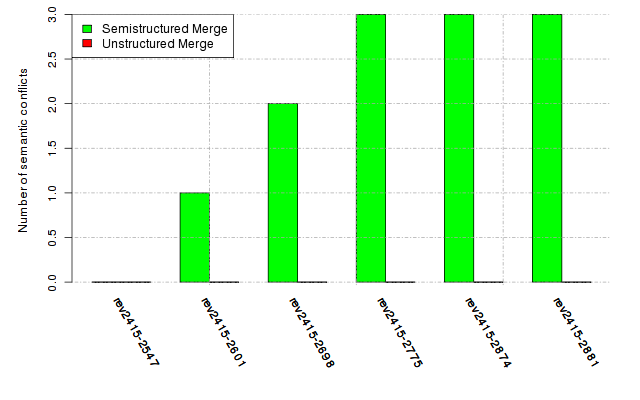
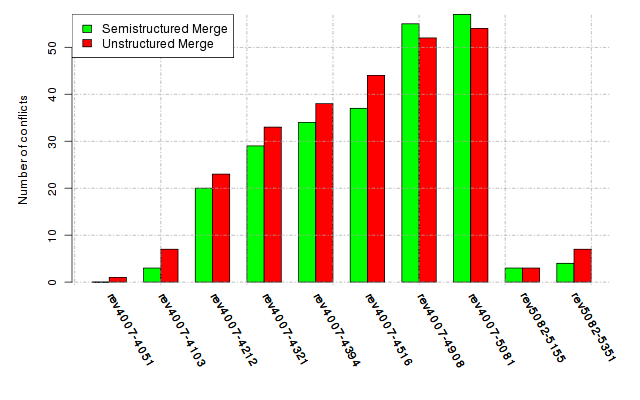
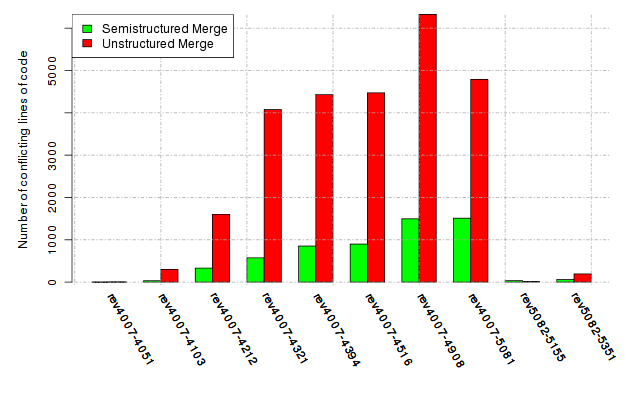
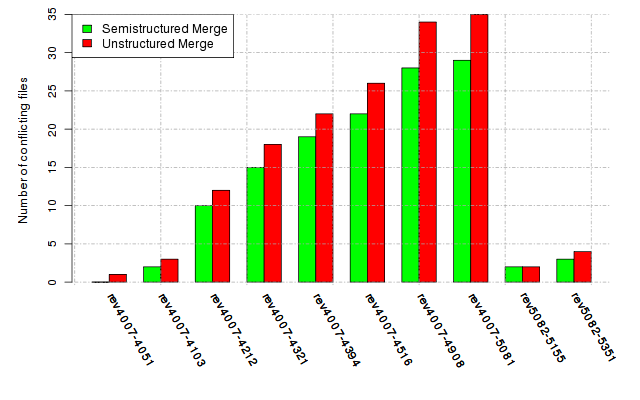
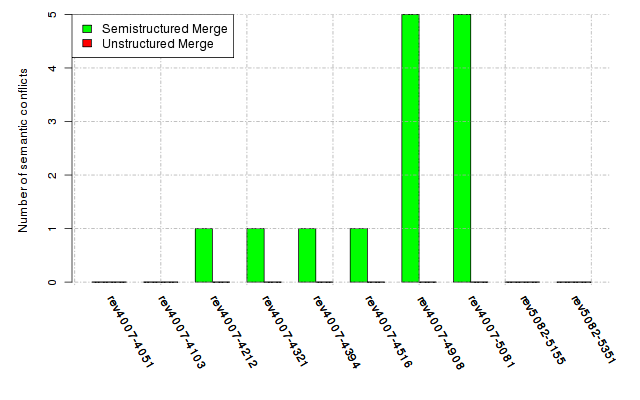
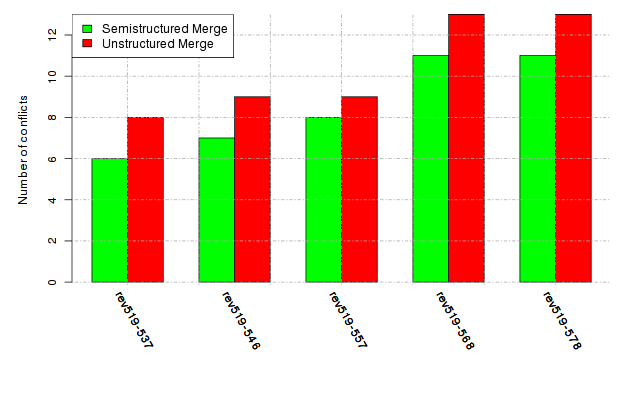
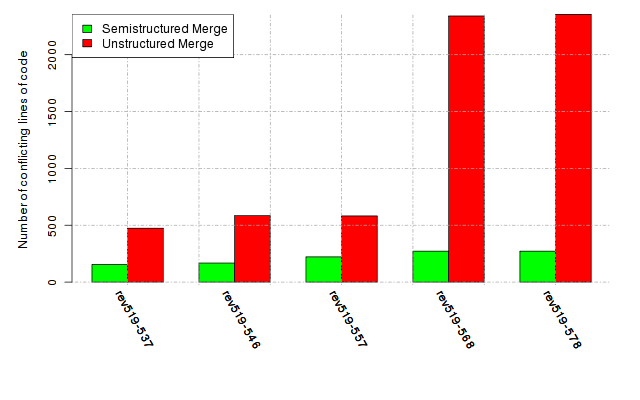
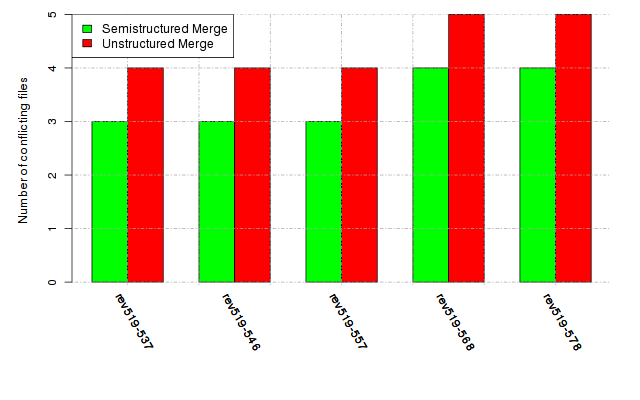
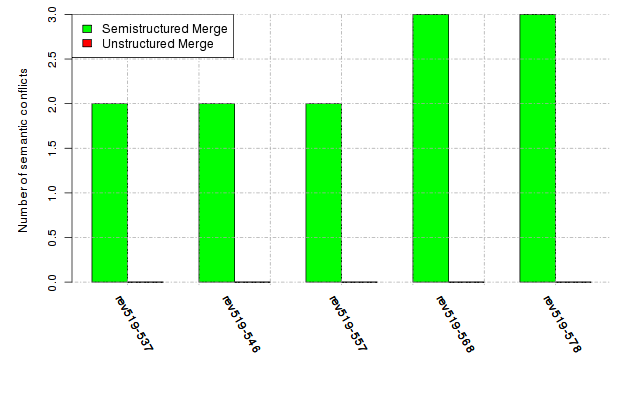
Below, we provide a set of diagrams containing information on the number of conflicts, conflicting lines of code, conflicting files, and semantic conflicts of all sample projects. Please click on the project names or diagrams to display the project's data collected during the empirical study.
|
|
Contact
For more information about the project, please contact: